
With the new Unstructed Extraction model, data can be extracted from text-heavy documents like the one shown above.
Unlock Valuable Insights with Unstructured Extraction
Companies are gathering and storing more data than ever, yet most of it remains unused.
But why does all this data get neglected?
The answer is that most of that data is unstructured, which is difficult to process without the proper tools. Unstructured documents are typically text heavy, and also frequently include numeric information, or even graphs and images. For this reason, unstructured data is a gold mine of knowledge—yet it remains untapped.
What is Unstructured Extraction?
This is where Hyperscience comes into play. Our brand new Unstructured Extraction model (released in our latest version) extends the extraction of pre-defined fields to unstructured documents.
When looking for specific data across a large number of text-heavy documents, the new model will read through these documents to locate the indicated data.
For example, say you’re processing a mortgage application and wish to extract the loan-to-value ratio buried within the application. After you’ve annotated “loan-to-value” on a few documents as training examples, the Unstructured Extraction model is smart enough to learn how to locate and extract this value from large sections of text in other documents.
Additionally, Unstructured Extraction can be used for:
- Processing very long documents: There is no constraint on the number of pages for documents users can extract information from
- Understanding text and context with more subtlety: Unstructured Extraction can extract specific information based on the meaning of the text, not just the location of a field or hints (e.g. “Recipient Address”)
- Extending the maximum number of words in a field: Unstructured Extraction allows for the extraction of fields up to 100 words in length
Benefits of Unstructured Extraction
Unstructured documents do not follow a specific format or structure, which means they can include free-form text, tables, images, and other content. These documents contain valuable information that can provide insights into customer needs, industry trends, and competitive landscapes.
The Unstructured Extraction machine learning model unlocks the ability for businesses to leverage the information that was hidden inside unstructured documents. By using Unstructured Extraction, organizations can gain a deeper understanding of their business operations and make data-driven decisions where it was previously too costly or time consuming for humans to extract manually.
How Does Unstructured Extraction Work?
The Unstructured Extraction model is based on a language model (the same type of technology that powers ChatGPT), pre-trained on more than 5 million documents. As such, its ability to understand text and language subtleties considerably improves over previous technology.
The product experience for this new model is nearly identical to previous releases, with the main difference being found in the annotation UI. Users can now annotate text in the middle of a paragraph, or even a paragraph made up of a few sentences.
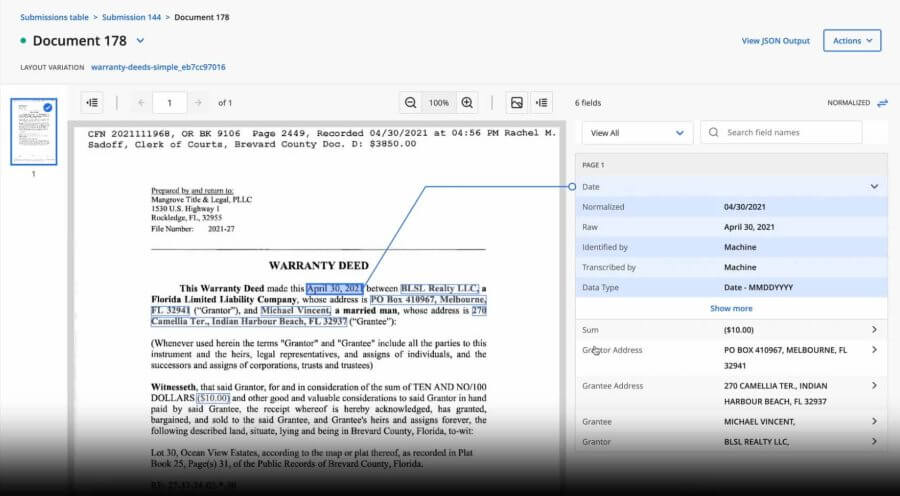
A text heavy document showing how Unstructured Extraction can extract data from the middle of dense paragraphs.
Because this model is more complex than previous offerings, it requires more computing power. For this reason, the Unstructured Extraction model is currently only available in Hyperscience’s SaaS offering, which uses an accelerated GPU to deliver this cutting edge technology at scale.
Getting Started with Unstructured Extraction
The ability to process unstructured documents is critical for organizations looking to automate their document processing operations and gain insights from their data.
Unstructured Extraction is available now to help organizations unlock the data trapped in unstructured documents. With this feature, businesses can automate the extraction of data from unstructured documents—saving time, reducing costs, improving accuracy, and enabling better decision-making.
To see a demo and learn more about how your business can benefit from Unstructured Extraction, contact us here.
