
The Rapid Rise of Data
Driven by rapid technological advancements, the once modest stream of information has now transformed into a deluge of data. Increased connectivity resulted in a data explosion. IoT devices, wearables, video footage, social media, recorded conversations, among others, contribute to this data glut, and the transition from data scarcity to surplus brought a new challenge. It’s not just about gathering data anymore—it’s about making sense of it, unveiling patterns, and ultimately, finding the golden needle of insight in the constantly-growing haystack.
IDC’s Global DataSphere, which forecasts the amount of data that will be created on an annual basis, predicts that through 2026, data will grow at a compound annual growth rate (CAGR) of 21.2%. This includes structured and unstructured data, but unstructured data—which includes things like emails, images, and or audio recordings—overwhelmingly dominates, accounting for more than 90% of the data created each year.
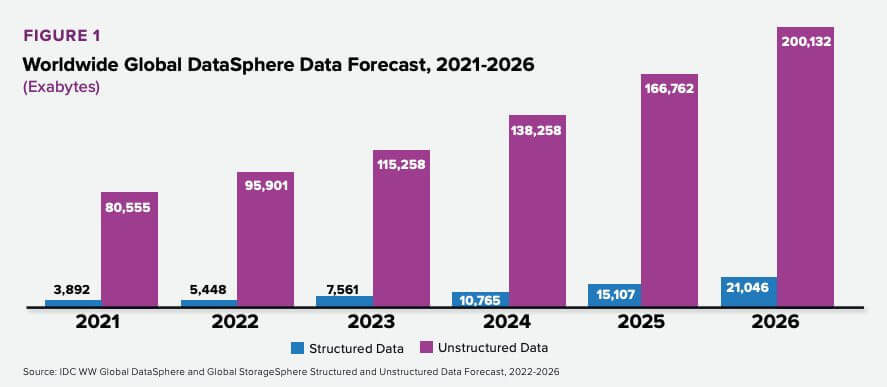
All this unstructured data poses significant challenges to business. Extracting meaningful insights from sources like text, images, and audio demands sophisticated tools and techniques. The absence of a standardized structure hinders efficient analysis, making data integration and interpretation complex. Unstructured data also requires substantial storage and processing resources, driving up costs.
Historically, the solution to these challenges was to hire data experts. Data scientists and engineers would wade through all this data to present it in a digestible way to the rest of an organization. Dashboards, charts, and tables were manually built by linking every possible database in order to paint the fullest picture. And as a result, the demand for data engineers and scientists grew, and so did their price tag, further increasing data-associated expenses.
And now, we’ve reached critical mass. Sure, you could keep throwing more people at the problem, but that’s going to be increasingly cost prohibitive, and it won’t be any help when you need to scale. So where is it that all this data can really be used effectively?
The answer lies with AI.
Using Your Data to Fuel AI Models
If AI is the solution to the growing data problem, then why haven’t enterprises been able to deploy AI models? The truth is building and deploying AI models is hard, and findings from a Dimensional Research report back this up. The report found that eight out of 10 organizations working with AI and machine learning said those projects had stalled.
A new school of thought called data-centric AI presents a new way for organizations to think about implementing AI solutions. So what is data-centric AI? According to the Data-Centric AI Community, “Data-Centric AI is the process of building and testing AI systems by focusing on data-centric operations (think cleaning, cleansing, pre-processing, balancing, and augmentation) rather than model-centric operations (like hyper-parameters selection, architectural changes).”
In layman’s terms, data-centric AI stresses that if you want a high-performing AI model, you need high-quality data.
Why Use Your Own Data?
So when there are already so many off-the-shelf data models you can use, what’s the advantage in creating your own?
Training your own custom machine learning models gives your business a competitive edge—something that’s very difficult to achieve with generic solutions from most AI vendors. When you create personalized models from your own data, you can tailor them to fit your exact needs and processes. This provides much more control over how the models behave, which boosts how accurate and relevant their predictions and decisions are.
Building these models in-house also provides an advantage in the way of intellectual property. As these “custom-fit” models learn and improve over time, they’ll help you understand your operations and customers even better. And with privacy and security concerns on the rise, keeping the model training in-house gives you better control over sensitive information.
What are the Challenges in Creating AI Models from Your Own Data?
You likely already have data that can be used to create a strong AI model, as well as the in-house expertise to annotate that data for AI models to train on. However, finding high-quality data can feel like searching for a needle in a haystack. Some of the challenges to be aware of when using your own data are:
Data Volume: Enterprises have large amounts of data that make it difficult for them to find dataset with good representation of the entire range of data. What makes this problem even harder is that the data is always changing making it difficult to keep up with all the new variation of data being seen. (ex. New vendor means new invoices)
Time & Money: Getting high quality annotation data can be an expensive and time consuming experience. Only individuals in your business understand how to interpret your data and ensuring that their expertises is accurately represented in the training data is difficult.
Complex Databases: Annotations and data can exist in different systems of record requiring complex data pipelines and storage solutions.
Poor Visibility: Model errors can generally be linked to poor annotation data and debugging model performance is often spent on going through annotation data to find and correct bad annotations.
However, just because there are challenges doesn’t mean something can’t be done. On the contrary, that’s why advanced solutions like Hyperscience exist.
How Hyperscience Helps You Use Your Data
Hyperscience is the platform to help you turn your data into AI models. Our entire model training workflow is centered around your data, making it as easy as possible for organizations to create accurate AI models.
To help businesses make sense of their data, we take on the full lifecycle of data preparation— whether it’s data upload, data annotation, or annotation cleansing—and ultimately plug it directly into a model training pipeline. This means that your team doesn’t have to invest in a full MLOps stack and can focus on making sure the data and annotations powering the model are accurate for your use case.
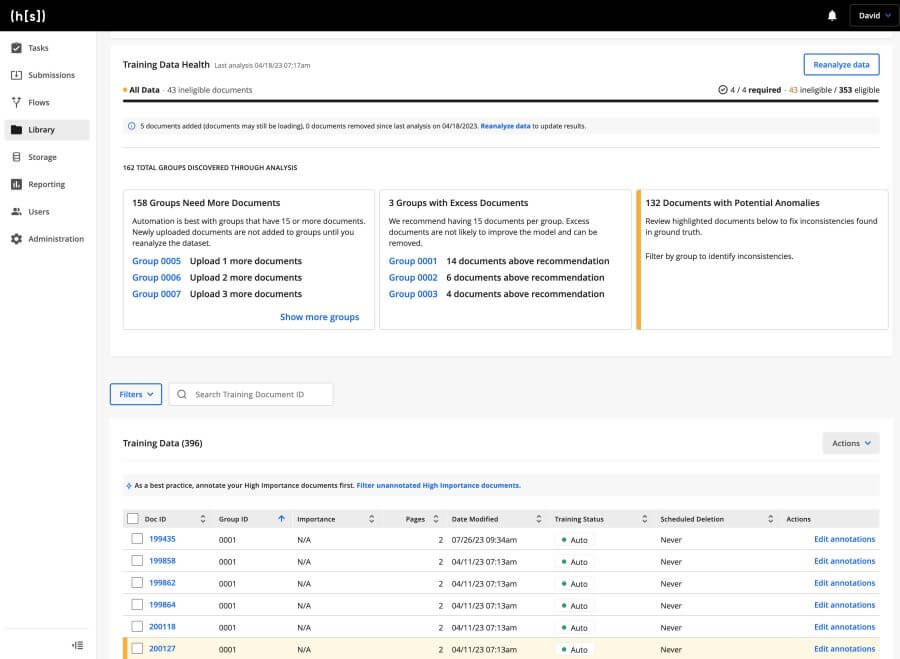
Recent advancements have enriched our platform with features that simplify the management of the model lifecycle for your teams. Notable among these enhancements are:
- Data Selection: Our latest update introduced the Training Data Curator, which empowers your teams to swiftly identify data requiring labeling to construct a top-notch dataset.
- Accelerated Labeling: Through our platform, your knowledge workers can now annotate data more rapidly than ever with guided data labeling, where the shift from annotator to reviewer accelerates data preparation.
- Annotation Quality: Lastly, ensuring accurate annotations is paramount. Our labeling anomaly detection includes tools that identify and flag annotations necessitating correction.
These features (among others) make it much easier to use the data you’ve collected in a meaningful way. AI models built from your own data can be used to automate many business processes—increasing efficiency company wide, and opening up new opportunities for those who were previously stuck crawling through data.
Getting Data Under Control with Smarter Solutions
Thankfully, the era of manually wrestling with massive datasets is giving way to the automation prowess of AI. By emphasizing the pivotal role of high-quality data in building AI models, organizations can effectively automate complex processes in a cost-effective and scalable manner. And with platforms like Hyperscience streamlining the data preparation process, businesses can focus on refining their data and annotations to power accurate, high-performing models.
