
Training data is the fuel that powers AI/ML model performance. But annotating all this data is time consuming, and doesn’t always result in significant performance improvements. Not all training data is created equal, and some data provides better training context than others. With Hyperscience’s new Training Data Curator, Hyperscience will tell you what data is most valuable to annotate.
Here’s what it looks like in action.
What is Training Data Curator?
To understand why not all data is created equal, let’s consider a scenario where we’re training a model to count the number of petals on a flower. We’ll use the following dataset of flowers as our training data.

While we could spend the time and effort to annotate all of the flowers, annotating them all would be redundant, and wouldn’t provide additional information for the model to train on. Consider the group of yellow flowers in the top left corner. They’re quite similar, and annotating all of them doesn’t provide any new information than if just one from that group was annotated.
So to annotate this dataset more efficiently, we should only annotate the flowers that are sufficiently different from one another. This gives our model enough data diversity to understand how different flowers look and to learn how to count petals across our dataset.

To put this in the context of documents, consider a case where a model is being built to extract vendor information (such as name, address, phone number) from an invoice. If we annotated only invoices with similar formats, our model will not have enough context to extract information for other vendors we may run into. Annotating invoices across different formats will give the model much more variety of examples to train on and thus result in a higher performant model.
What are the Benefits of Training Data Curator?
With our new Training Data Curator capabilities, Hyperscience can analyze training data and tag which documents are of high importance for annotation. As a result, you will be able to:
-
Annotate Less Training Data
With Training Data Curator, Hyperscience will intelligently recommend which data is important to annotate in order to create a high performing model in as few as 100 documents
-
Deploy Production Models Faster
Preparing training data is the bottleneck to getting a model to production. This is due to limited subject matter experts available to annotate, or the large volume of data to annotate. With the Training Data Curator, you’ll be able to move faster by annotating less data than previously versions of Hyperscience required.
How does Training Data Curator work?
Once you’ve uploaded your dataset into Training Data Management, all you have to do is click “Analyze Data” within the Training Data Health widget and Hyperscience will run its algorithms using your training data. This process should only take a couple of minutes, and at the end you’ll see the Training Data Health overview, like below:
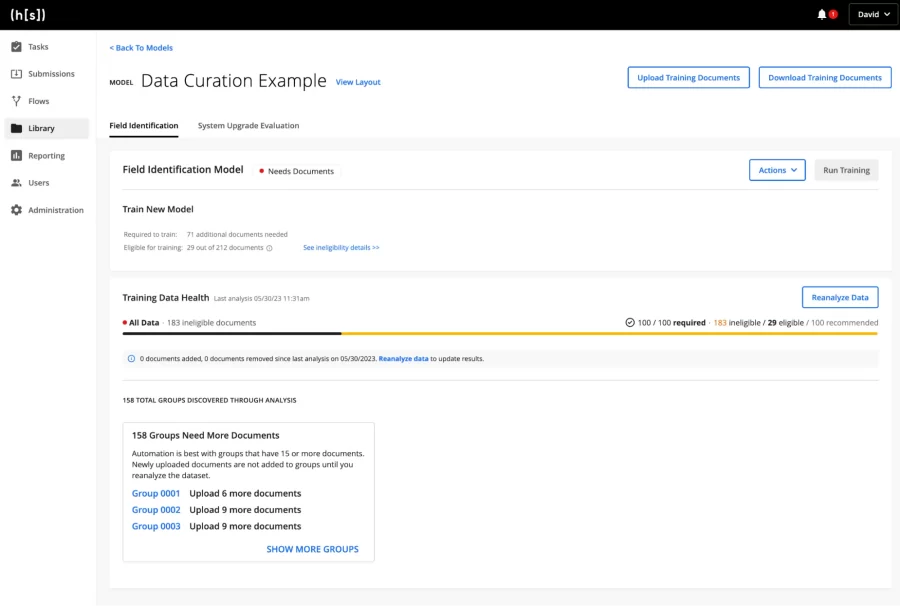
In this example, we’ve uploaded 212 documents to our model for training, but after running our Training Data Curator, Hyperscience is recommending that only 100 of those documents actually be used. To see which documents are recommended for annotation, simply scroll down to the training data table and filter for documents that are tagged with “high” importance.
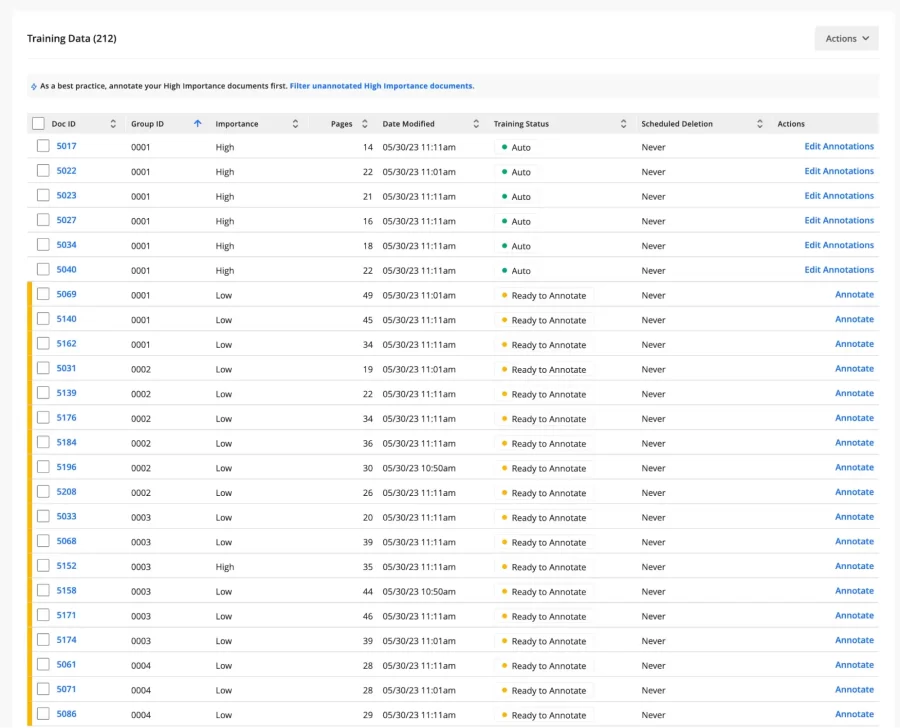
Now you can really focus your teams and begin annotating those documents for your model training purposes.
Accelerate Model Deployment with the Upcoming Release
With Hyperscience’s new Training Data Curator, you can annotate less data and get your models to production faster with no decrease in performance. This feature launches next week in the latest Hyperscience release. To start using it now, please contact your customer success representative.
