
The time it takes to fully process documents has a material impact on the performance of a business. For example, if document submissions halt during processing, it can result in an inconsistent level of performance—leading to breached SLAs and frustrated customers. For our customers, lowering document processing time positively influences the speed and volume of service they provide.
In our upcoming release, we’re introducing capabilities with the Hyperscience workflow engine (known as “Flows”) that increase visibility and help prevent halted document submissions. Flows support highly customized operations that can be performed at any step during document processing. An example of a common operation is to perform validations on extracted data with other data residing in an external database.
Auto-retry for Flows
A common point of failure for a flow execution is when the connection to a source (such as a database) can’t be established. These failures can occur during maintenance periods or during periods of heavy use when the infrastructure can’t keep up with demand. In either case, a flow designed to use an external service while processing a document submission may fail if it can’t reach that external service—and the submission halts as a result.
To make flow executions more resilient toward this type of failure, our new functionality allows customers to set bespoke auto-retry policies for their flows. When auto-retry is enabled, the flow will retry the operation of a block any time a block in the flow encounters an error. Users can define how many retry attempts they wish to be made, as well as how long the wait period should be between retries.
For more customized control, the auto-retry policy can be applied at three different levels:
- Across all flows in the Hyperscience instance: All flows will have the same auto-retry policy set by default
- At the flow level: Allows configuration of the number of retries and wait periods per flow
- At the individual block level: For isolating the application of the retry policy for specific blocks, or to override the default flow-level policy for a designated block
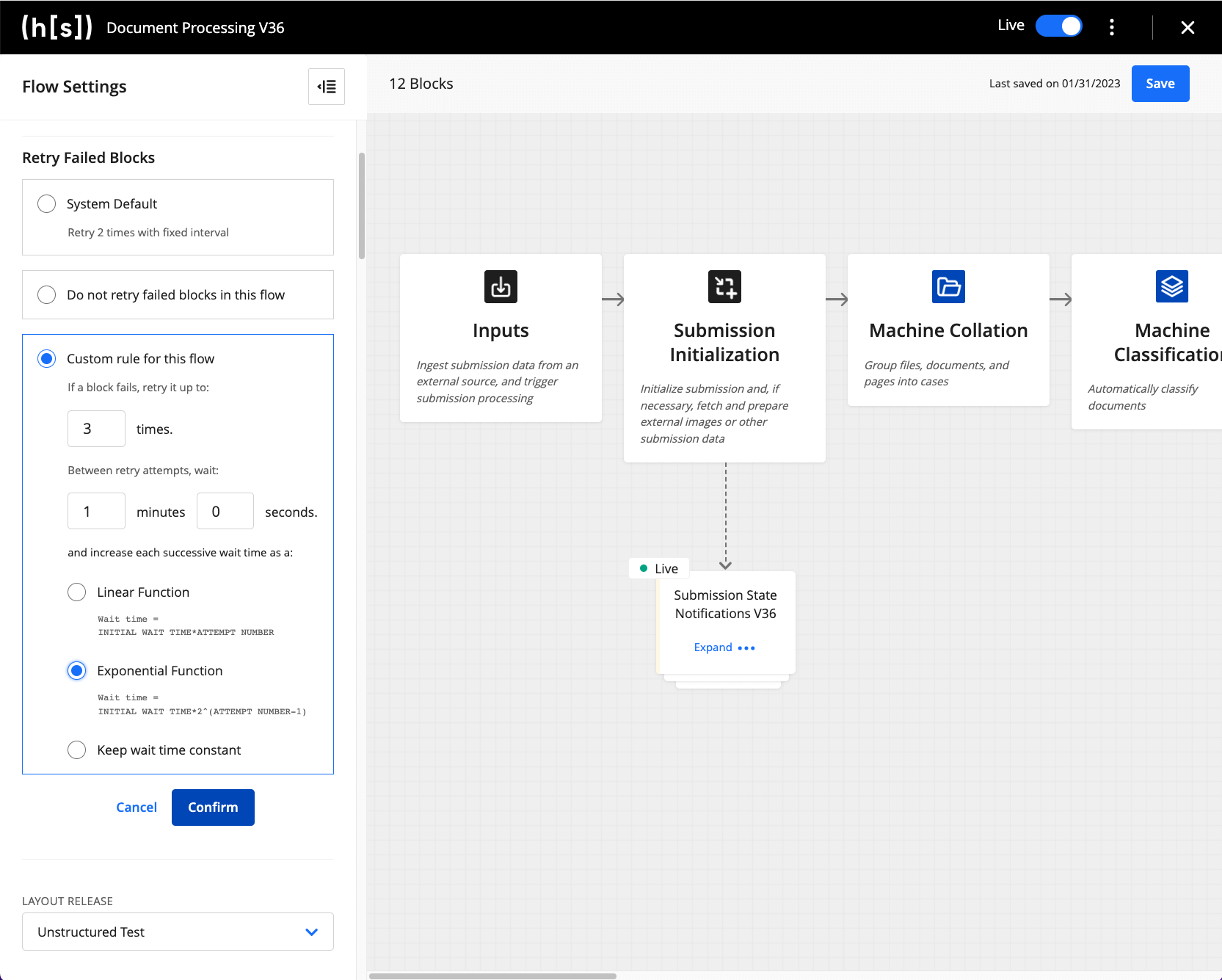
With an auto-retry policy enabled, any failures that occur within a block are retried in the background—there’s no action or monitoring required from users. This feature will substantially lower halted submissions in cases where intermittent outages occur with a flow’s dependent services.
Viewing Failed Flow Executions
Automated retry policies are a valuable tool, but they can’t fix everything – submissions can still halt for other reasons. These cases must be easily seen and reviewed in order to identify and fix. To help with this, we’re also introducing a new page in Hyperscience that allows users to view all flow executions.
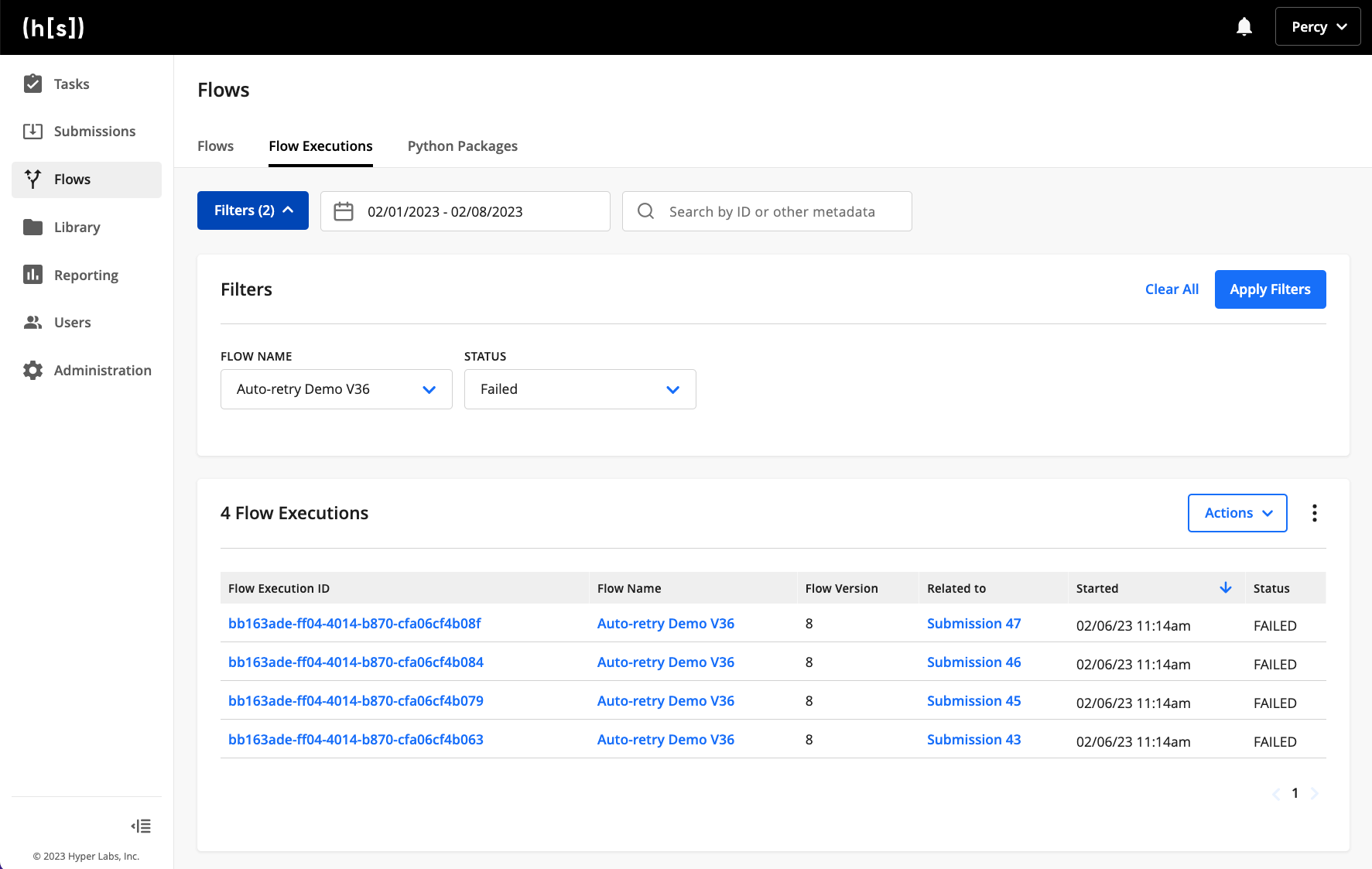
The Flow Executions list page displays all of the “flow runs”, most of which occur when submissions are processed in Hyperscience. By filtering, users can easily view the list of failed flow executions and which submission they are related to. Clicking on a flow execution ID navigates the user to the detailed Flow Execution page where they can identify which block failed and why. Deeper visibility is enabled via additional context on the page such as flow-level runtime errors and displaying the code that runs within each custom code block.
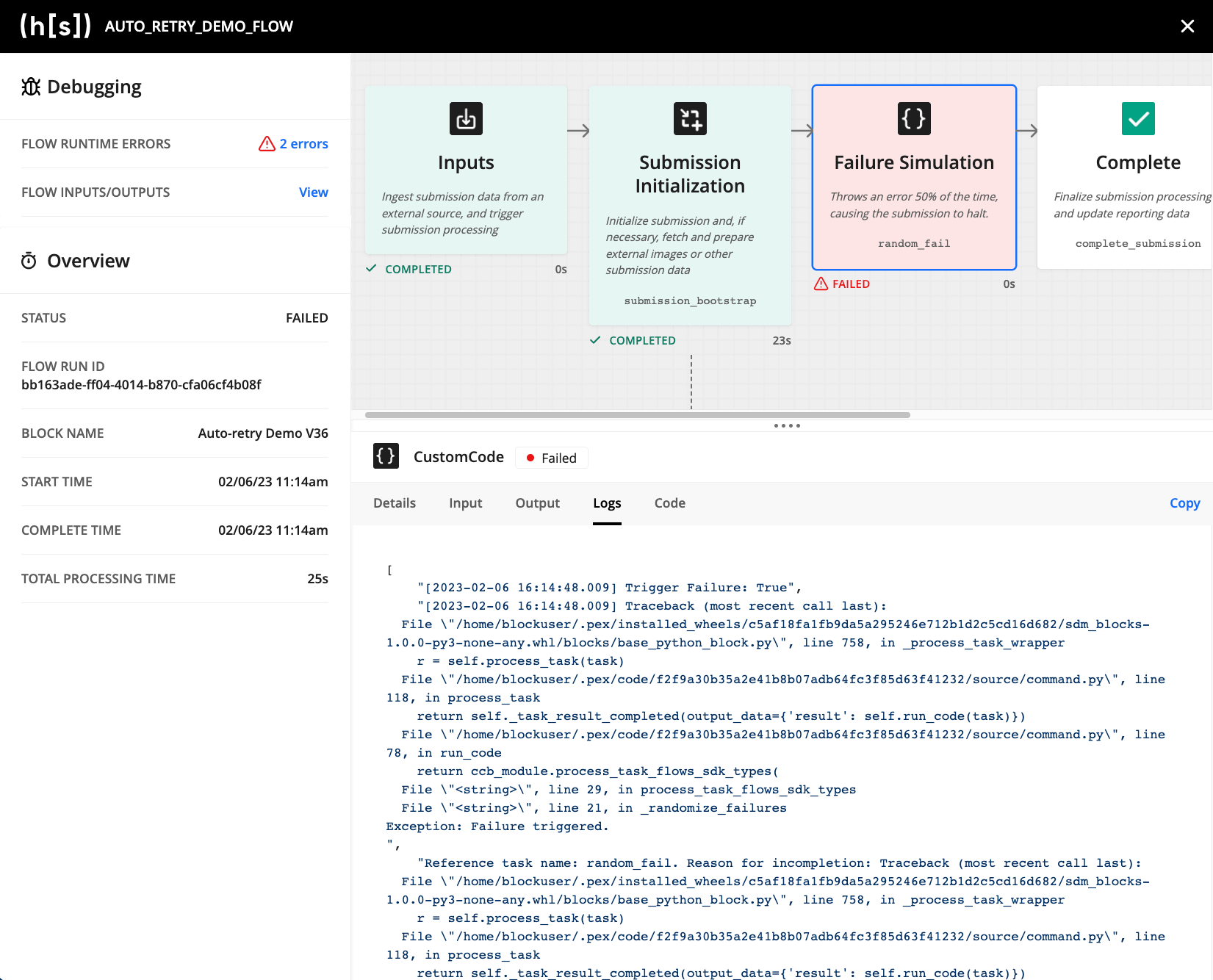
After identifying and addressing the error, users can easily retry all of the impacted failed flow executions.
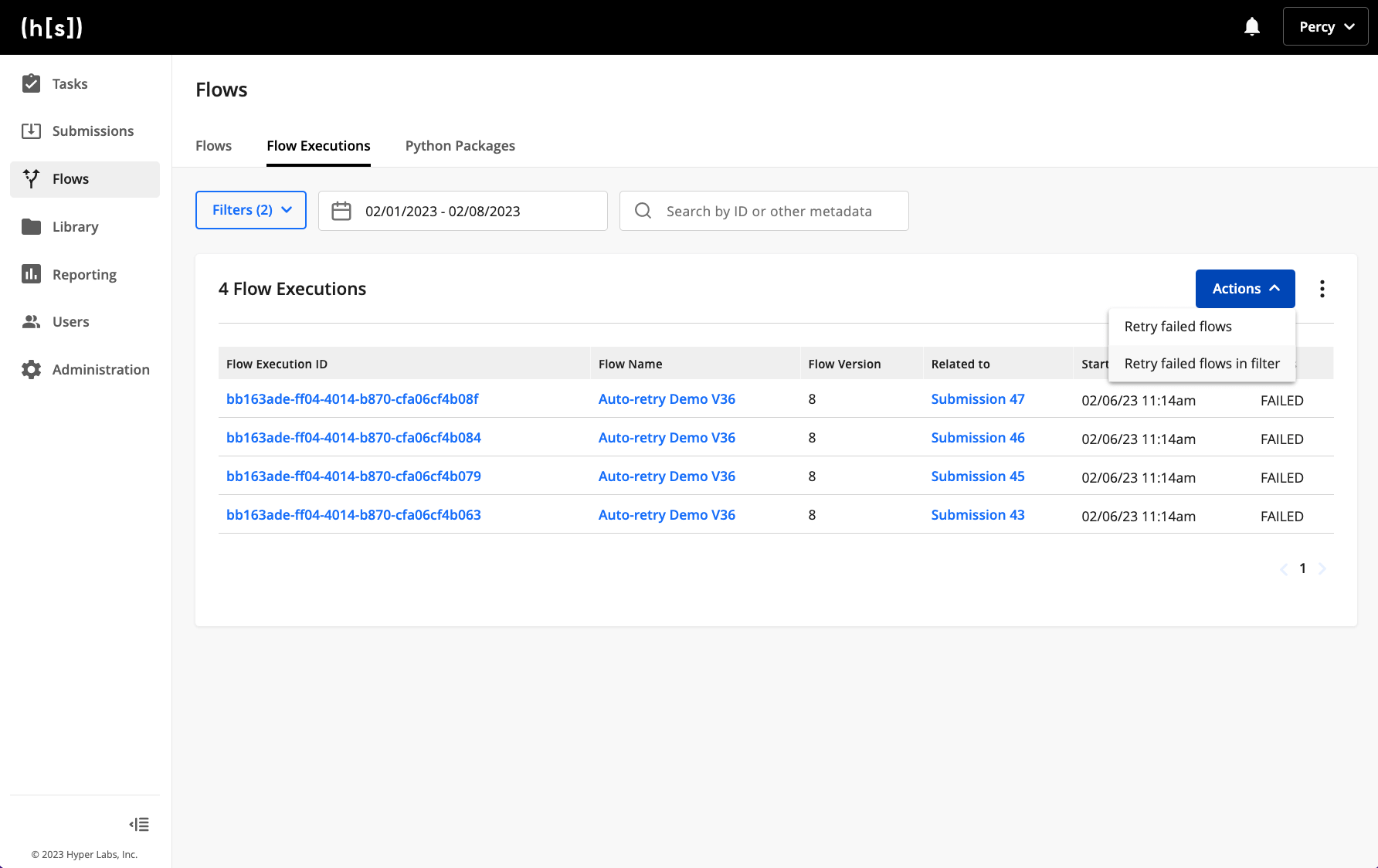
To investigate halted submissions, some users may start by filtering through the Submissions list page. Thus, we’ve included a deep link to the Submissions Filtering control to guide users to the failed Flow Executions list page.
There’s More in Store
We’re excited to hear the thoughts from our customers with these capabilities shipping in R36, and what improvements we can make to further reduce and aid in resolving halted submissions. A future capability we’re investigating aims to reduce the time a submission is halted by sending proactive notifications to our users when a flow execution fails (after exhausting a configured auto-retry policy.) If you have thoughts or are interested in any of the capabilities discussed here, please reach out to us via your Customer Experience contact or contact us here.
