
In the last few years, intelligent document processing (IDP) has seen rapid growth in adoption rate as organizations deal with high volumes of complex documents. IDP software enables organizations of all sizes to remove costly and inefficient manual processes, improve data accuracy, and use their existing employees more effectively.
According to Gartner, the IDP market is growing more than 100% year over year, and is projected to reach $4.8 billion in 2022, proving that businesses are rapidly adopting document processing technology as the necessity for automating complex use cases continues to grow.
And there are no signs of this growth slowing down. Times of economic uncertainty create even more demand for document processing technology. It’s in these times that public and private organizations look to increase efficiencies and cut costs by targeting inefficient, manual processes.
What Is Intelligent Document Processing?
Intelligent document processing helps transform structured (forms), semistructured (checks, paystubs, invoices, etc…) and unstructured data (deeds, medical records, emails, contracts, etc…) from a variety of document formats into digitized and actionable information. It uses a combination of technologies, such as optical character recognition (OCR), natural language processing (NLP), computer vision, machine learning (ML) and artificial intelligence (AI), to scan, classify, identify, and extract data.
IDP solutions understand a wide variety of document formats and the content it contains; extracting, validating, and integrating quality data into appropriate business processes and downstream systems.
Additionally, IDP overcomes the limitations of legacy document capture tools like RPA and OCR and streamlines document processing using human-in-the-loop (HITL) machine learning to handle exceptions and to train and improve its capabilities over time.
Intelligent document processing relies on multiple different technologies to operate:
Computer Vision is a technology which is able to derive meaningful information and understanding from videos and digital images, and take actions based on that information
Machine Learning is a branch of artificial intelligence based on the idea that systems can learn from data and uses computer algorithms to identify patterns and make decisions with minimal human intervention
Deep Learning is a machine learning technique that imitates the way humans gain certain types of knowledge—it learns by example. In deep learning, models are trained by using a large set of labeled data and neural network architectures that contain many layers, achieving very high levels of accuracy
OCR is a type of software that converts images of text into machine-readable forms.
How Does Intelligent Document Processing Work?
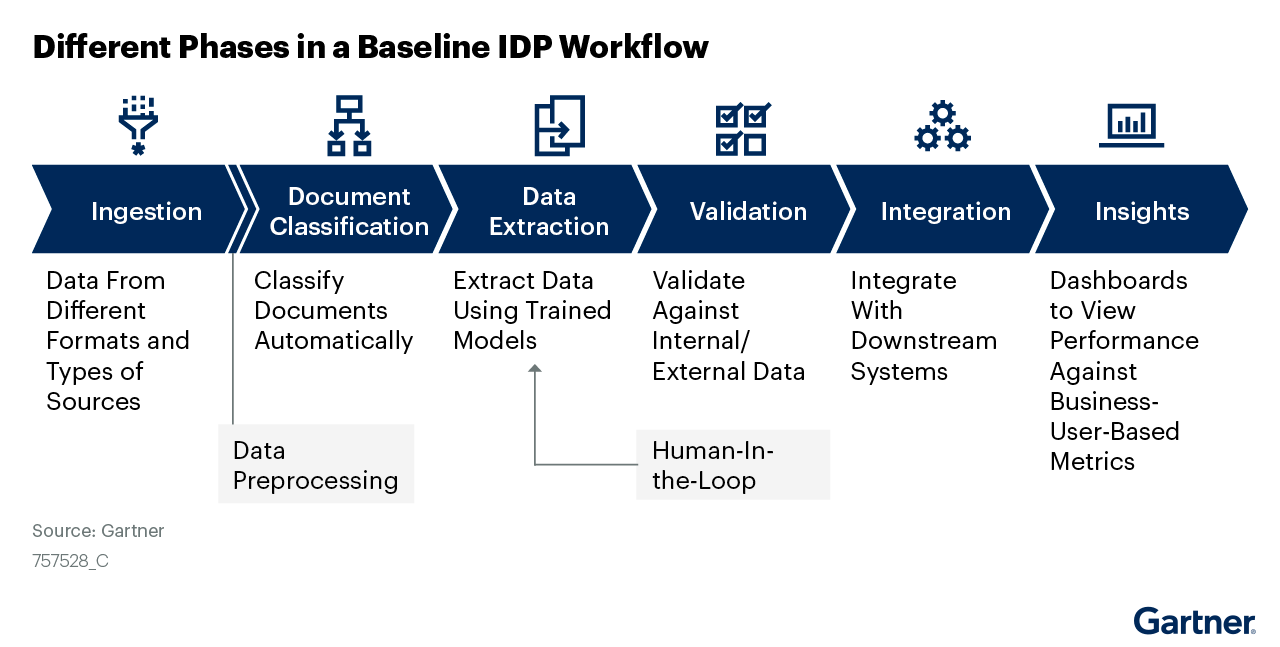
IDP solutions use machine learning to extract data from documents to support automation efforts. IDP generally consists of the following five steps.
- Data Ingestion & Preprocessing
Data is captured from several content types and prepared for processing. This preparation includes merging/splitting documents, and corrections to low quality renders. Some solutions also provide tools for data labeling and annotation, often done by a human-in-the-loop (HITL). - Document Classification
Documents are then classified into different categories. This can be a manual or an automatic process, with advanced solutions offering suggestions for categories based on existing taxonomies. At this stage, humans are typically involved in document category creation and definition. - Data Extraction
Machine learning extracts data from various content types and supports the handling of diverse formats. During this step, humans train the machine learning model to identify fields for extraction. - Data Validation and Feedback
Extracted data is then validated against internal/external data. Human input is used to deal with outliers, preprocessing, classification, extraction quality improvement, and additional ML model training. - Data Integration
Validated data is sent to downstream applications for use. Common intelligent document processing integrations include customer service platforms, data enrichment tools, and RPA solutions. Ultimately, this is where the data lands for decision making and business process improvement.
Industries That Use Intelligent Document Processing
Many industries stand to benefit from the use of intelligent document processing. Many large industries already have IDP software in place to accelerate critical processes and serve customers more efficiently.
Intelligent Document Processing in Banking
Banks are inundated with documentation. From credit card applications, new account opening requests, and changes to personal details, these tasks take up a large amount of employee time when done manually.
Introducing intelligent document processing to the banking industry can help better leverage internal bank data and streamline the process of acquiring necessary customer information, allowing lenders to review applications faster.
Intelligent Document Processing in Financial Services
Huge volumes of complex and sensitive data make the finance industry an ideal candidate for IDP. It is a perfect solution for automating increasingly complex financial services processes such as mortgage processing, account opening, or account servicing.
To stay competitive, financial institutions need to streamline document-heavy processes without compromising on accuracy or customer service. IDP can help speed up document processing, improve the accuracy and timeliness of decisions, and free up resources to focus on delivering frictionless customer experiences that the competition can’t match.
Intelligent Document Processing in the Public Sector
Every day, public sector organizations must process millions of forms, applications and images to meet the needs of citizen-centric workflows such as benefits claims or tax returns. These documents come in a wide variety of formats, often with poor readability and high variability, making it difficult efficiently process and extract data for downstream usage.
These outdated, manual workflows and legacy approaches contribute to a massive data backlog and lead to an information bottleneck that results in strained systems, overworked employees, and citizens frustrated by delays.
Using IDP, government agencies can unlock the potential hidden in their huge volumes of data, gain efficiencies, improve citizen and employee satisfaction, and deliver better outcomes.
Intelligent Document Processing in the Medical Industry
The medical industry stands to gain significant efficiency improvements through the use of intelligent document processing.
Not only does IDP assist in the processing of detailed patient notes, prescriptions, appointments, and medical records, it also helps organizations support employees with greater opportunities.
Many medical organizations have opted to use automated document processing to ensure that employees’ registration documents, identification documents, and other HR-based requirements are processed quickly and without error. Decreasing the time it takes to manually complete these admin-heavy tasks saves organizations a great deal of time—a necessity when a matter of minutes can mean the difference between life and death.
Intelligent Document Processing in Transportation and Logistics
The sheer volume of shipped goods and their accompanying documents make the logistics sector an industry ripe for IDP. Incorrect information at any stop can delay shipments and have dire consequences for your freight and your customers.
To stay on top of demand and increase resilience to market changes, the transportation and logistics sector can benefit from implementing IDP to automate document-heavy processes to remove friction in their operations without compromising on accuracy or customer service.
Benefits Of Intelligent Document Processing
For organizations seeking the long-term value of automating labor-intensive administrative tasks, here are some of the benefits of using IDP.
- Improve Efficiency
Intelligent document automation solutions require minimal human intervention, allowing existing employees to work more efficiently. This leads to faster response times, better customer service, and increased revenue - Reduce Costs
By automating the manual effort needed for document processing, IDP minimizes repetitive, low-value tasks and reduces the associated overhead costs. The savings brought on by document process automation and IDP are felt most keenly during times of business growth or when there are seasonal surges in volume that historically require hiring temporary staff. - Minimize Mistakes
It’s an unfortunate reality that as the speed of work increases, so does human error. For employees who may already be at full capacity, pushing for even more productivity can take them to their breaking point, leading to harmful effects on customer satisfaction. Introducing the use of an intelligent document processing platform helps organizations to minimize the risk associated with poor data entry, while increasing the speed at which tasks can be carried out. - Increase Data Security and Control
If customer or employee data is lost or misplaced, it can leave businesses vulnerable to security breaches or legal action. Intelligent document processing allows a business to digitize so that the physical copy can be disposed of in the correct manner.
How Hyperscience Can Support Your Business With Intelligent Document Processing
As a leading provider of IDP solutions, Hyperscience offers superior accuracy, human/AI collaboration, flexibility, and scalability, making it an excellent choice for organizations looking to modernize their operations.
With its AI-powered technology, Hyperscience extracts data from complex and constantly changing documents with the highest accuracy in the industry, minimizing the need for manual data entry and validation and freeing up employees to focus on other mission-critical areas of work. Where legacy solutions focus on automation rates and throughput with little regard for the errors that come out the other end, Hyperscience’s focus on accuracy ensures that data is accurate from the start, providing shorter document handling times and less data cleanup.
And by taking a human centered approach to automation, Hyperscience helps humans and machines work together to achieve even greater results. Machine learning models learn from human feedback, improving in efficiency over time, and in turn humans can focus on the tasks that require a human touch, such as decision-making and problem-solving.
The platform can be easily configured to meet specific business needs, including application customization, several deployment options, integration with other solutions, future scalability, agility, and cost effectiveness.
AI-powered IDP solutions offer federal agencies a path to modernization and increased efficiency. By leveraging the superior accuracy, flexibility, scalability, and human/AI collaboration of platforms like Hyperscience, organizations can save time and money, reduce errors, and improve decision-making.